Asymmetric Reinforcement Learning under Partial Observability
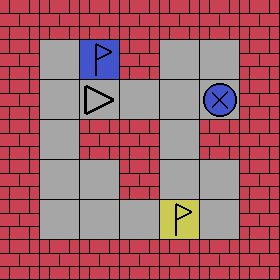
State of GridVerse-Memory-Four-Rooms-7x7, a partially observable control problem that requires information-gathering and memorization.
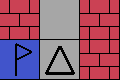
Observation of GridVerse-Memory-Four-Rooms-7x7.
Partially observable agents are by definition unable to observe the environment state when training and/or executing online, i.e., in the environment itself. However, offline training algorithms running in simulated environments are able to access the simulation state and use it to help train the agent through a mechanism called asymmetry. Asymmetry originates from actor-critic algorithms, and is based on training a history policy \(\pi(h)\) using non-history information, e.g., a state critic \(\hat V(s)\). This is possible because the critic is a training construct that is only used during training, and not execution. The privileged state information has the potential to greatly improve the training process, its sample efficiency, and/or the performance of the resulting agent. However, prior work on asymmetric reinforcement learning is often heuristic, with few (if any) theoretical guarantees, and is primarily evaluated empirically on selected environments. One of my primary focuses in this line of research is in analyzing the theoretical correctness of existing asymmetric algorithms, and in developing new algorithms that use state information correctly.
Asymmetric A2C.
In this work, we first analyze a basic variant of asymmetric A2C found in the literature that employs state critics \(\hat V(s)\), and expose fundamental theoretical issues tightly associated with partial observability. We then propose a simple adjustment that involves the use of history-state critics \(\hat V(h, s)\), resolves all theoretical issues, and is better is better suited to train partially observable agents. The main takeaways of this work are that:
State critics \(\hat V(s)\) are fundamentally inadequate for problems that exhibit non-trivial amounts of partial observability.
History-state critics \(\hat V(h, s)\) are correct alternatives that avoid theoretical pitfalls and provide concrete benefits.
Asymmetric DQN.
Value based algorithms like DQN train a single value model \(\hat Q(h, a)\) and typically lack the dual modeling aspects of actor-critic algorithms, and seem inherently incompatible with asymmetry. In this work, we import asymmetry into the world of value-based algorithms by employing a supplementary history-state model \(\hat U(h, s, a)\) used exclusively as a training construct, and develop the theory of asymmetric value-based policy improvement using a bottom-up approach, starting from basic solution methods like asymmetric policy iteration (API), and working our way to a state-of-the-art asymmetric deep value-based algorithm called asymmetric DQN (ADQN). The main takeaways of this work are that:
We develop the theory of asymmetric policy improvement that make use of state information.
We develop a series of algorithms that result in ADQN, a modern state-of-the-art deep reinforcement learning:
Baisero, Daley, and Amato, “Asymmetric DQN for Partially Observable Reinforcement Learning,” in Proceedings of the Conference on Uncertainty in Artificial Intelligence, 2022.
Lyu, Baisero, Xiao, and Amato, “A Deeper Understanding of State-Based Critics in Multi-Agent Reinforcement Learning,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2022.
Baisero and Amato, “Unbiased Asymmetric Reinforcement Learning under Partial Observability,” in Proceedings of the Conference on Autonomous Agents and Multiagent Systems, 2022.
Reward-Predictive State Representations
Predictive state representations (PRSs) are models of controlled observation sequences that lack a notion of latent state, i.e., given an action sequence \(\bar a\), they are able to produce the same distribution over observation sequences \(\Pr(\bar o\mid \bar a)\) as any given partially observable Markov decision process (POMDP). Due to their stateless nature, and the fact that they are based exclusively on observable data, it is considered to be simpler to learn PSR models than POMDP models. However, we show that PSRs are not intrinsically able to model the reward process of arbitrary POMDPs, i.e., the history reward function \(R(h, a)\), and are therefore not suitable to model arbitrary partially observable control tasks. In this work, we develop reward-predictive state representations (R-PSRs) an extension to PSRs that is able to appropriately models arbitrary reward processes in addition to the observation processes, finally making them stateless representations that are equivalent in all observable aspects to POMDPs. The main takeaways of this work are that:
PSRs are not able to correcly model the reward process \(R(h, a)\) of any given POMDP.
R-PSRs explicitly incorporate rewards in their design, allowing them to accurately model any given POMDP.
The derivation of R-PSRs is extremely similar to that of PSRs, and R-PSRs share a lot of the properties of PSRs.
It is possible to adapt algorithms developed for PSRs to R-PSRs, as we do for value iteration (VI).
Baisero and Amato, “Reconciling Rewards with Predictive State Representations,” in Proceedings of the International Joint Conference on Artificial Intelligence, 2021.
Predictive Internal State Models
Sequential decision making under partial observability relies on the agent’s ability to aggregate the observable past into a concise and informative representation. A good representation is one which (a) is concise, (b) is informative, and (c) satisfies the Markov property. A representation that satisfies all these desireable properties is the belief-state \(b(h)\), which encodes the distribution over states given the observed history. It is well-known that the belief-state is a sufficient statistic of the history for the purpose of control.
Uh-oh!
This content is currently being written or updated, and will be restored shortly.
Baisero and Amato, “Learning Complementary Representations of the Past using Auxiliary Tasks in Partially Observable Reinforcement Learning,” in Proceedings of the Conference on Autonomous Agents and Multiagent Systems, 2020.
Baisero and Amato, “Learning Internal State Models in Partially Observable Environments,” in Reinforcement Learning under Partial Observability, NeurIPS Workshop, 2018.
Decoding the Geometry out of Relational Descriptions of the Environment
Human cooperation often relies on a specific type of interaction, in which one agent (Alice) defines a task via a high-level description of the goal state, and the other agent (Bob) interprets the goal state from the description and performs the task. For this to take place, Alice has to be able to encode her desired geometric state and compress it into a predicate-based relational description, while Bob has to be able to take such description and decode it into a belief over the possible wanted geometric states. In this project, we define a simple way to decode a predicate-based relational description of the environment into a mixture-of-Gaussians distribution of the resulting geometric state.
The relational description of a scene is converted into a joint
distribution of object geometric properties (position, size, etc).
Identification of Unmodeled Objects via Relational Descriptions
Successful human-robot interaction requires advanced communication algorithms capable of parsing human language, and to associate symbolic components of language with perceptual representations of objects in the environment. The identification problem, defined as the problem of correctly identifying an object out of many given a relational description, is one instance where this is required.
The description problem is similar to a standard classification problem where each object in the environment represents a separate class, with the the key difference that the number of classes and their associated semantics are not predefined, but rather vary for each instance of the problem. As a consequence, the output classes also have features associated with them, e.g. a target mug has measurable features relative to its color, shape, or position, that are useful and/or necessary for its identification among other objects and among other mugs.
Full pipeline composed of perception, segmentation, identification and grasp of unmodeled objects.
In this work, we address the identification problem, and propose a
logistic-regression-like stochastic model that outputs a likelihood over all
objects in a scene. The model exploits contextual information by weighing the
significance of each description predicate by how much other objects in the
scenario exhibit the property encoded by the same predicate. This allows the
descriptions to be flexible and incomplete, so long as they focus on
combinations of properties that make the target object distinguishible from the
others in the environment.
Baisero, Otte, Englert, and Toussaint, “Identification of Unmodeled Objects from Symbolic Descriptions,” arXiv preprint arXiv:1701.06450, 2017.
Temporal Segmentation of Concurrent Asynchronous Demonstrations
Sequential instruction set extracted from demonstration.
Complex manipulation tasks are typically composed of a large number of concurrent and asynchronous interactions with the interaction, called interaction phases. The success of an autonous system that learns from human demonstrations hinges on its ability to semantically parse the desmonstrations and deconstruct them into their atomic components, thus learning a representation for how and why they are performed.
In this work, we use a conditional random field (CRF) to model and infer interactions between objects from their joint motions. The model is applicable both to hand-object pairs, in order to extract purposeful interactions with the environment, and to object-object pairs, to extract changes of state in assembly tasks.
Baisero, Mollard, Lopes, Toussaint, and Lütkebohle, “Temporal Segmentation of Pair-Wise Interaction Phases in Sequential Manipulation Demonstrations,” in Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems, 2015.
Mollard, Munzer, Baisero, Toussaint, and Lopes, “Robot Programming from Demonstration, Feedback and Transfer,” in Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems, 2015.
Implicit Feature Space Embeddings for Sequential Structures
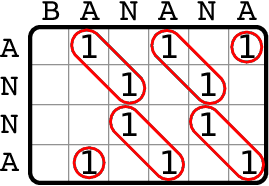
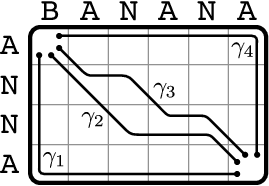
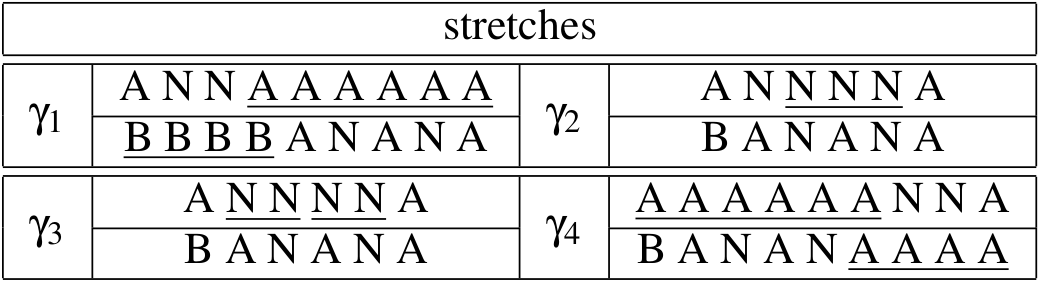
Similarity encoded by combinations of matching stretches.
A number of machine learning methods (e.g., SVNs and Gaussian Processes) rely on data via a kernel function that can be interpreted as a similarity measure and implicitly represents a dot product between data instances. In this MSc project, I developed the path kernel, a novel kernel function for sequential data.
Given two strings \(s,t\in\Sigma^+\) composed of symbols from a lexicon set \(\Sigma\), we can broadly measure the similarity between \(s\) and \(t\) by considering the number of matching substrings, their length, and their location in the path matrix. The path kernel \(k_\texttt{PATH}\colon \Sigma^+ \times \Sigma^+ \to\mathbb{R}\) takes this basic idea and generalizes it in two important ways. First, it considers values produced by a lexicon kernel \(k_\Sigma\colon \Sigma\times\Sigma\to\mathbb{R}\) rather than strict binary matching. The second, is that it considers all possible paths from the top-left to the bottom-right of the path matrix, aggregating all the values found along the paths, weighing each path based on its general shape.