Make sure you check the syllabus for the due date. Please use the notations adopted in class, even if the problem is stated in the book using a different notation.
Each predictor will correspond to a decision stump, which is just a feature-threshold pair (f,t); in other words a single-split decision tree. Note that for each feature, you may have many possible thresholds which we shall denote . Given an instance, a decision stump predict +1 if the input instance has a feature value exceeding the threshold otherwise, it predicts -1. To create the various thresholds for each feature you should
Run your Adaboost code on the Spambase dataset
You should think carefully about how you can efficiently generate the required results above. For example, I would suggest keeping a running weighted linear prediction value (before thresholding at zero) for each training and testing instance: when each new round predictor is created, you can simply update your running weighted linear prediction value and then easily compute training and testing error rates (by thresholding these values at zero), as well as testing AUCs (by ranking the instances by these values).
UCI datasets: AGR,
BAL, BAND, CAR, CMC, CRX, MONK, NUR, TIC, VOTE. (These are
archives which I downloaded a while ago. For more details and
more datasets visit http://archive.ics.uci.edu/ml/).
The relevant files in each folder are only two:
* .config : # of datapoints, number of discrete
attributes, # of continuous (numeric) attributes. For the
discrete ones, the possible values are provided, in order, one
line for each attribute. The next line in the config file is the
number of classes and their labels.
* .data: following the .config convention the
datapoints are listed, last column are the class labels.
You should write a parser that given the .config file, reads the
data from the .data file.
A. Run the
Adaboost code on the UCI data and report the results. The
datasets CRX, VOTE are required, rest are optional
B. Run the algorithm for each of the required datasets using c% of the datapoints chosen randomly for training, for several c values: 5, 10, 15, 20, 30, 50, 80. Test on a fixed fold (not used for training). For statistical significance, you can repeat the experiment with different randomly selected data or you can use cross-validation.
C: Active Learning Run your code from PB1 on Spambase, CRX, VOTE dataset to perform Active Learning. Specifically:
- start with a training set of about 5% of the data (selected randomly)
- iterate: train the Adaboost for T rounds; from the datapoints not in the training set; select the 2.5% ones that are closest to the separation surface (boosting score F(x) closest to 0) and add these to the training set (with labels). Keep training the ensemble, every T boosting rounds add data to training set until the size of the training set reaches 60% of the data.
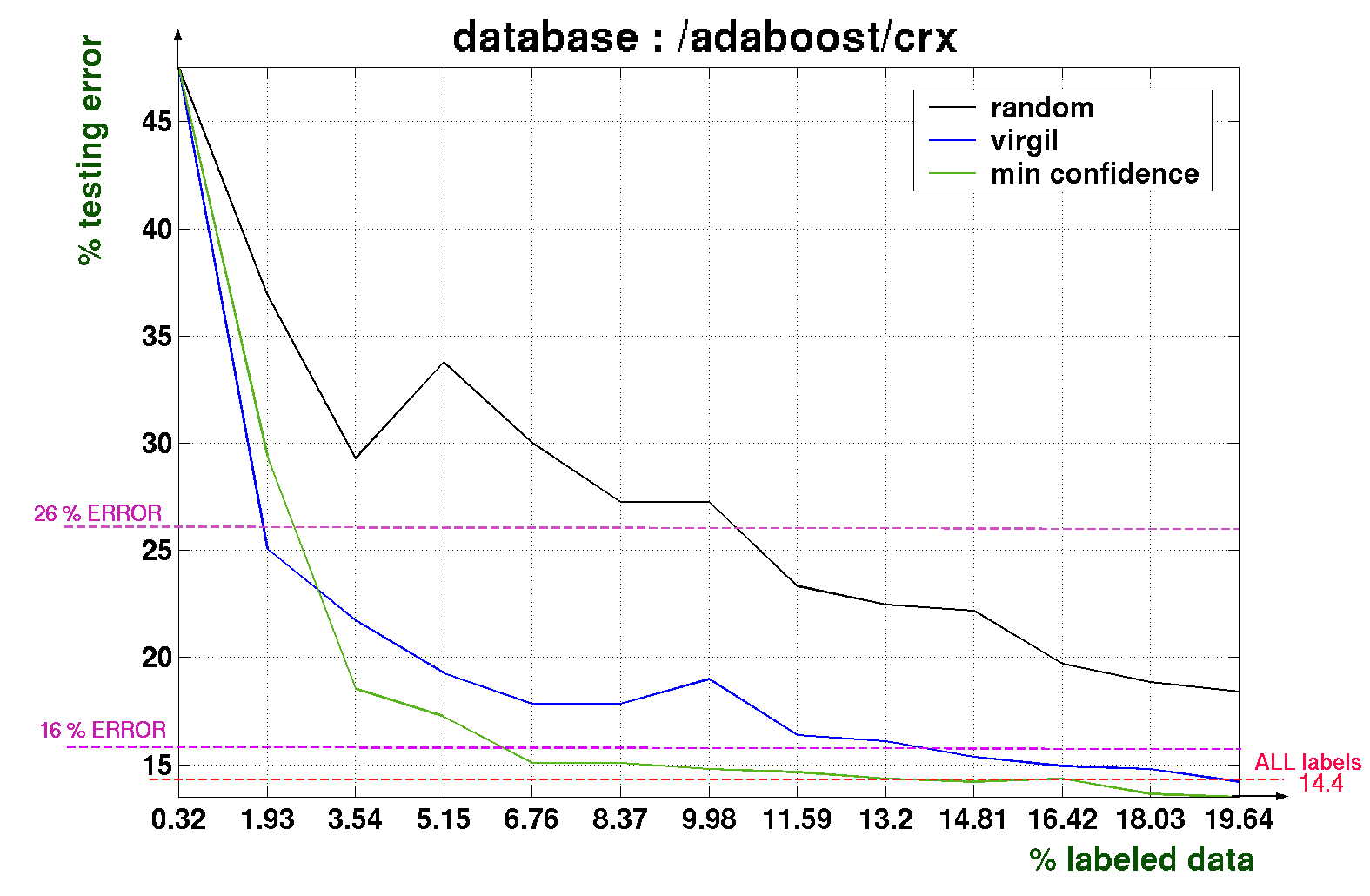
How is the performance improving with the training set increase? Compare the performance of the Adaboost algorithm on the c% randomly selected training set with c% actively-built training set for several values of c : 5, 10, 15, 20, 30, 50. Perhaps you can obtain results like these
Run Boosting with ECOC functions on the 20Newsgroup dataset with extracted features. The zip file is called 8newsgroup.zip because the 20 labels have been grouped into 8 classes to make the problem easier. The features are unigram counts, preselected by us to keep only the relevant ones.
There are no missing values here! The dataset is written in a SPARSE FORMAT: "label featureId:featureValue featureId:featureValue featureId:featureValue ...". The features not listed are not missing values, they have zero values which were not written down to save space. In a full-matrix format, these values would be 0.ECOC are a better muticlass approach than one-vs-the-rest. Each
ECOC function partition the multiclass dataset into two labels;
then Boosting runs binary. Having K ECOC functions means
having K binary boosting models. On prediction, each of the K
models predicts 0/1 and so the prediction is a "codeword" of
length K 11000110101... from which the actual class have to be
identified.
You can use the following setup for 20newsgroup data set.
- Use the exhaustive codes with 127 ECOC functions as described
in the ECOC paper, or randomly select 20 functions.
- Use all the given features
- For each ECOC function, train an AdaBoost with decision stumps for 200 or more iterations
The above procedure takes a few minutes (Cheng's optimized code, running on a Haswell i5 laptop) and gives us at least 70% accuracy on the test set.
Run bagging on Spambase dataset. Compare results with
boosting.
Run gradient boosting with regression trees on housing dataset.
Essentially repeat the following procedure i=1:10 rounds on the
training set. Start in round i=1with labels Y_x as the original
labels.
The overall prediction function is the sum of the trees. Report
training and testing error.
Run Boosting with ECOC functions on the Letter Recognition Data Set (also a multiclass dataset).
- Implement rankboost algorithm following the rankboost paper and run it on TREC queries.
Run gradient boosting with regression stumps/trees on 20Newsgroup dataset dataset.
{kind=link}