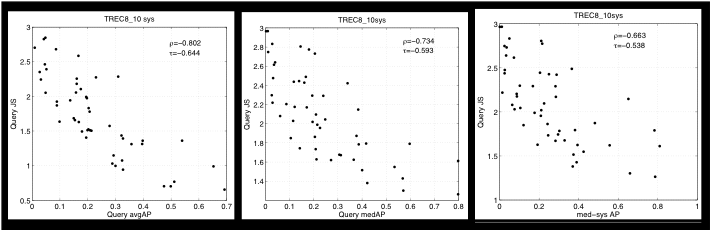
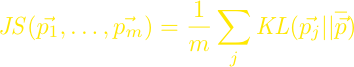Jensen-Shannon divergence
By appropriately employing Jensen-Shannon divergence to measure the “diversity” of the returned results, we demonstrate a methodology for predicting query difficulty whose performance exceeds existing state-of-the-art techniques on TREC collections, often remarkably so.